
Projets réalisés
(2003-2016)
histograph - graph-based exploration and crowd-based indexation
histograph is an open source application for the graph-based exploration and crowd-based indexation of multimedia documents.
histograph was initially developed as one of two demonstration applications for the FP7-funded research project CUbRIK, which aimed to find new pathways for the combination of human and machine computation in multimedia search. The first version of the application offered a pipeline that put humans in the loop: the algorithmic detection and identification of faces in historical photographs was supported and enhanced by the work of a generic crowd of users and expert human annotators. Based on the idea of co-occurrence — all people that appear together in an image are related — an interactive graph was created that displayed these interconnections. The original demonstration version developed for the CUbRIK project is freely available for testing.
Since March 2015, histograph has been redeveloped with a new ambition: to provide an open source tool for the graph-based exploration and crowd-sourced indexation of the CVCE.eu’s cultural heritage objects, which include a variety of text types and photos.
A demo application is available for testing; you can find detailed information on the project page.
Exploration of cultural heritage documents based on co-occurrence graphs
histograph combines the graph-based exploration of larger cultural heritage collections with crowd-based indexation. The tool opens up a new perspective on the CVCE.eu’s collections, which comprise approximately 20 000 digitised text documents, photos, audio recordings and videos.
histograph adds an explorative approach to the hierarchically organised, expert-curated collections of CVCE.eu: users can decide what interests them and find their own path through the collections. A user who is interested in Pierre Werner will for example see a page similar to the screenshot below.
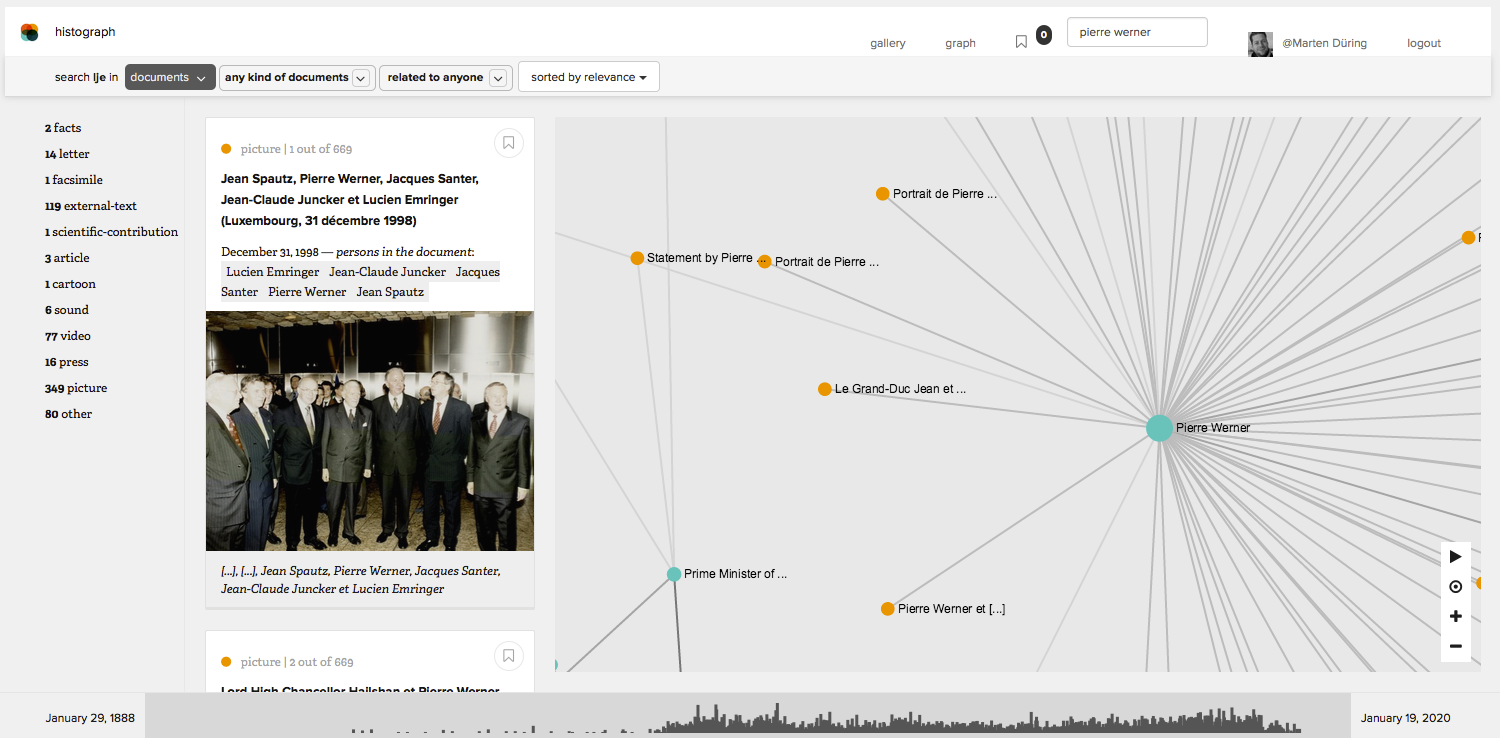
A search for ‘Pierre Werner’ yields an overview of all types of document in which the person is mentioned (left column), a list of related documents (middle) and an interactive graph of all documents and people that are mentioned together with ‘Pierre Werner’.
The first column provides an overview of all documents in which Pierre Werner is mentioned. The middle column lists all documents in which he is mentioned. The third column provides a graph of all documents and people that co-occur with Werner. In this case, co-occurrences are defined as mentions of entities in the same document.
histograph uses a Neo4j graph database to store relations between entities. This approach facilitates queries that would be computationally expensive in relational databases but are easily available in graph databases, such as the calculation of paths between entities that are not directly connected. Below we show the result of a query for all documents which connect three people. The left column now shows the list of selected people and the middle column the list of documents that mention two or more of the selected entities. The right column provides a graph of the co-occurrences and lets users select and further explore any relations which are of interest to them.
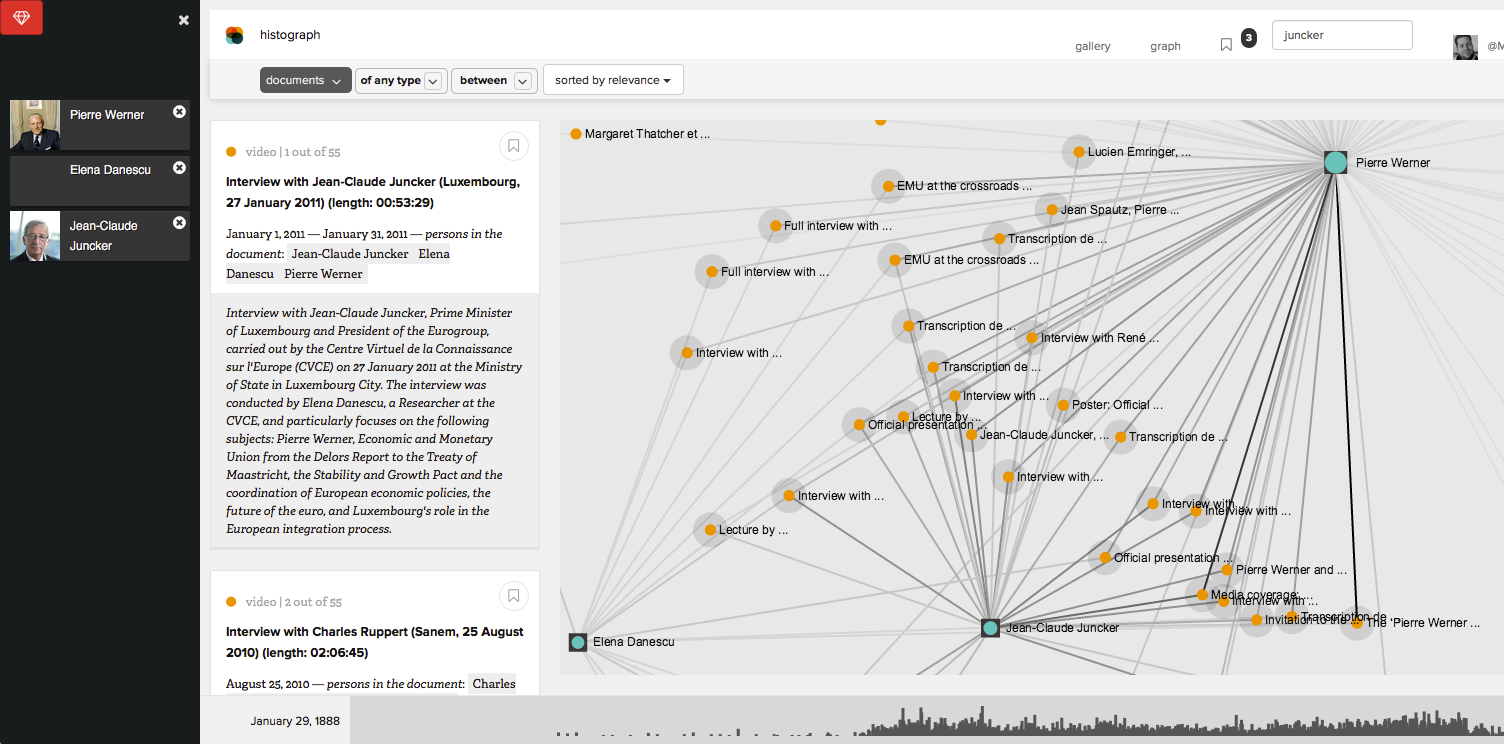
A query for paths between Pierre Werner, Jean-Claude Juncker and our colleague Elena Danescu reveals all relevant documents as well as an interactive graph of co-occurrences (who co-occurs with whom).
histograph enables an interest-driven exploration by users and provides them with an effective way to retrieve and explore any relationships which are of interest to them. Compared with the museum-like order of the traditional CVCE.eu collections, histoGraph models a more or less targeted visit to an archive which holds the promise of serendipitous discoveries.
Making sense of co-occurrences
Methods for the annotation of named entities such as people, institutions and places have reached a very high degree of maturity and are used in different applications. For histograph we tested a variety of web services for the detection and disambiguation of entities (NER), including TextRazor and YAGO. While these services perform well depending on the context of use (language, field, etc.), even in a best-case scenario they can only be used to identify the occurrence of an entity within a logical unit such as a text, not to clarify the nature of the connection between people, places and organisations that occur together in the same unit. In our previous experiences with the detection and identification of faces in historical image sets, the format and context of the images as official photographs of specific events enabled us to understand the nature of the relationship in a more straightforward way: the simple working hypothesis that people who co-occur together in a photo have some kind of connection proved to be very effective. In the case of texts, however, these semantics are significantly more complex.
We therefore decided to follow two paths, first based on the nature of the text document, where letters for example constitute a relationship between the sender and the receiver, and second through a mathematical modelling of the relationship based on the distance between entities in the text and their distribution within the corpus. The latter step became necessary as not all of our text documents fall in the category of clearly structured formats such as letters, and even if they do, a strictly format-based co-occurrence approach could conceal interesting relationships that would merit exploration, e.g. in our case a written exchange between two politicians where they discuss a third person.
Entities that appear together in a document are linked based on the assumption that their co-occurrence in the text is not arbitrary and that there is a high probability that they have something to do with each other. Despite all efforts to further specify the significance of such relationships, co-occurrences remain elusive:
- It is hard to further specify what ‘more or less connected’ means;
- It is hard to further specify what types of relationship are at play;
- It is hard to assess which relationships were missed because entities were named differently.
A graph of such data can only allow rather general statements: we can reasonably assume that entities which co-occur often are more connected than those which do not. We can also assume that entities which never co-occur are less connected or not connected at all. Finally, we can assume that entities which tend to cluster together are more likely to have something to do with each other, without further specifying their relationship.
In contrast, most Social Network Analysis (SNA) research questions require very well defined relationships since they treat social networks as models of highly complex social interactions. Here, a graph represents a meaningful reduction of such complexity and allows insights into specific dimensions of social relations. Graphs are used to represent and/or illustrate highly complex matters which are otherwise hard to express. Such data is typically generated and curated for the purpose of specific research questions and its value is limited to the context in which it was created.
CVCE.eu and cultural heritage institutions in general, however, address heterogeneous user groups and wish to make their data available to different audiences including educators, researchers and interested laypeople. A graph of relations between entities will therefore serve different purposes than it would in an SNA context. Here, graphs need not be meaningful models of social relations; rather they are multi-purpose tools that can be used to explore documents and accommodate widely differing interests. This means that it is impossible to predict which relations a user will consider relevant.
Against this background we embrace co-occurrences despite their inherent shortcomings and ambiguity. In order to improve the quality of the various relations we display, we need to balance a) higher quality or more meaningful relations and b) the potential to make highly unexpected yet meaningful discoveries in the data. In order to achieve this, we decided against a rigid ontology of relationship types, which would significantly limit the chances for unexpected discoveries beyond format-based assumptions (e.g. the sender/receiver relationship in a letter). Instead we use text synopses and full document text for the generation of relationships and filters on time periods, media types and entities in order to further specify our graphs. In addition, we use a twofold crowd-based approach: generic crowds help clean the data and report obvious mistakes, while expert crowds provide high-quality annotations which require highly domain-specific knowledge.
The resulting graphs can be considered as hybrid products, based both on co-occurrences and on user specifications. Such graphs, we argue, have the potential both to meet the need for the automated generation of graphs and to provide meaningful structural information which can be the starting point for a deeper investigation of the documents.
Crowd-based indexation
Histograph combines tools for the automatic detection of named entities (people, places, institutions and dates), enrichment with DBpedia and VIAF with crowd-based annotations. By default, every automatically detected entity is indicated as pending validation by a human user. Automatic entity detection works very well overall but will always remain imperfect in places. To address this, HistoGraph depends on human validation and error correction.
Three different systems are in place to collect user input: questions on the overall validity of an entity (‘Is this a person?’), questions on the validity of an entity annotation in an object (‘Is this person mentioned here?’) and personalised notifications based on the previous actions of a user (‘User x added a person to a document you worked on. Can you confirm this annotation?’).
All annotations can be in one of three stages: not validated, validated or disputed. In addition, users are encouraged to fix mistakes themselves by annotating new entities and by flagging wrong entity types, fragments, duplicates or erroneous annotations. To avoid accidental annotations and reduce the risk of vandalism, histograph treats every annotation as a suggestion pending confirmation by other users.
We operate with two types of crowd task: tasks targeted at a generic crowd, which means that anyone is able to provide input, and harder, more challenging tasks, which target expert users. Users qualify for these expert tasks on the basis of their previous actions. For example, a user who annotates many documents associated with Pierre Werner will be asked to validate related annotations by others and to identify unknown entities in related documents
Project team
Dr Lars Wieneke
Dr Marten Düring
Daniele Guido
Selected Publications
To learn more about histoGraph and how it works email us at histograph [at] cvce.eu.
Jasminko Novak, Lars Wieneke, Marten Düring, Isabel Micheel, Mark Melenhorst, Javier Garcia Morón, Chiara Pasini, Marco Tagliasacchi, Piero Fraternali: histoGraph — A Visualization Tool for Collaborative Analysis of Historical Social Networks from Multimedia Collections, In: Proceedings of 18th International Conference on Information Visualization (IV), 2014. Conference location: Paris, France (also winner of the best paper award)
Lars Wieneke, Marten Düring, Ghislain Sillaume, Carine Lallemand, Vincenzo Croce, Marilena Lazzarro, Francesco Nucci, et al. Building the Social Graph of the History of European Integration. In: Social Informatics, edited by Akiyo Nadamoto, Adam Jatowt, Adam Wierzbicki, and Jochen L. Leidner, 8359:86–99. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer, 2014. http://dx.doi.org/10.1007/978-3-642-55285-4_7.